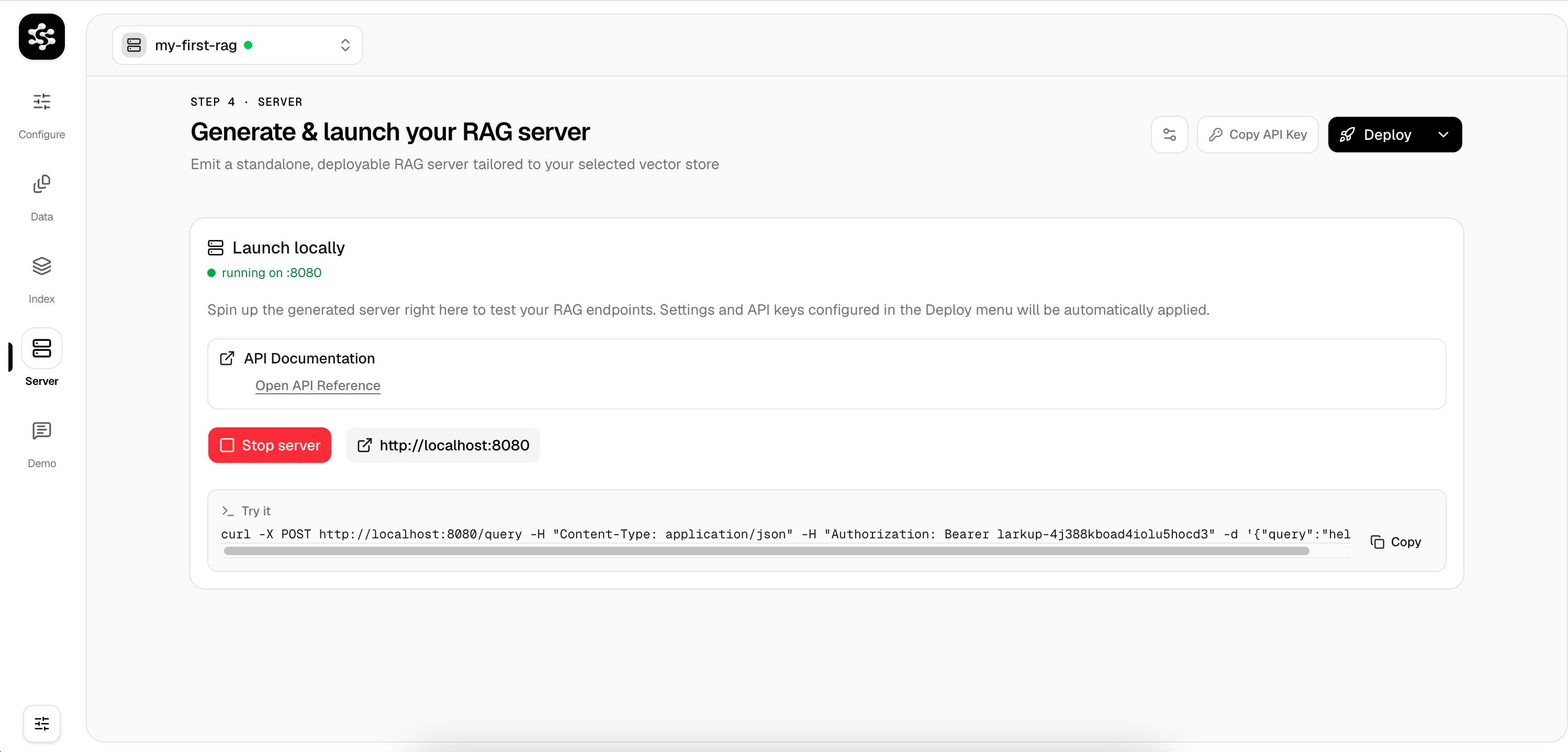
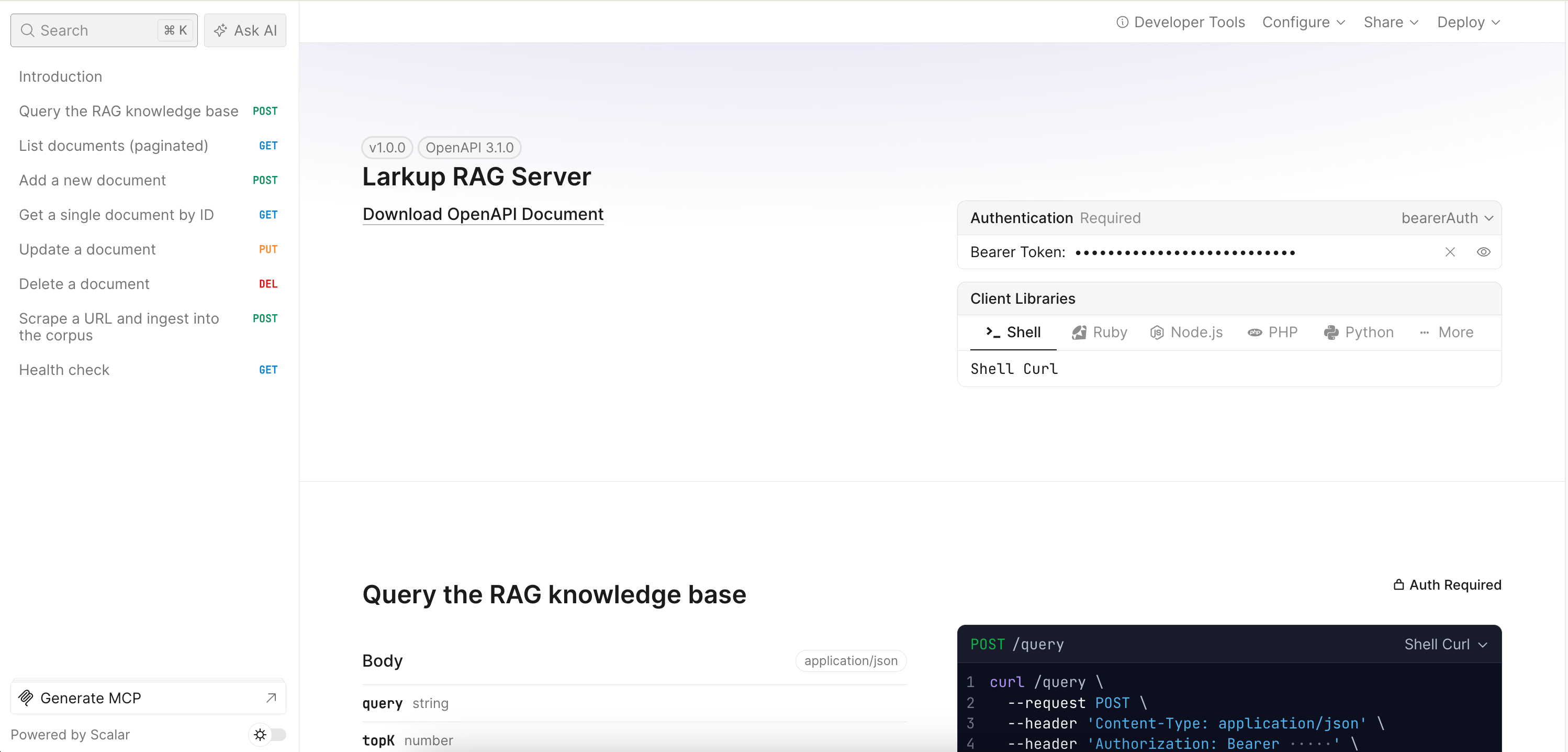
Create a Workspace
Launch the Web UI and create a workspace to encapsulate your configuration, data, and server.
Configure
Navigate to the Configuration tab. Select a Vector Store (e.g., LanceDB) and an Embedding Model (e.g., OpenAI).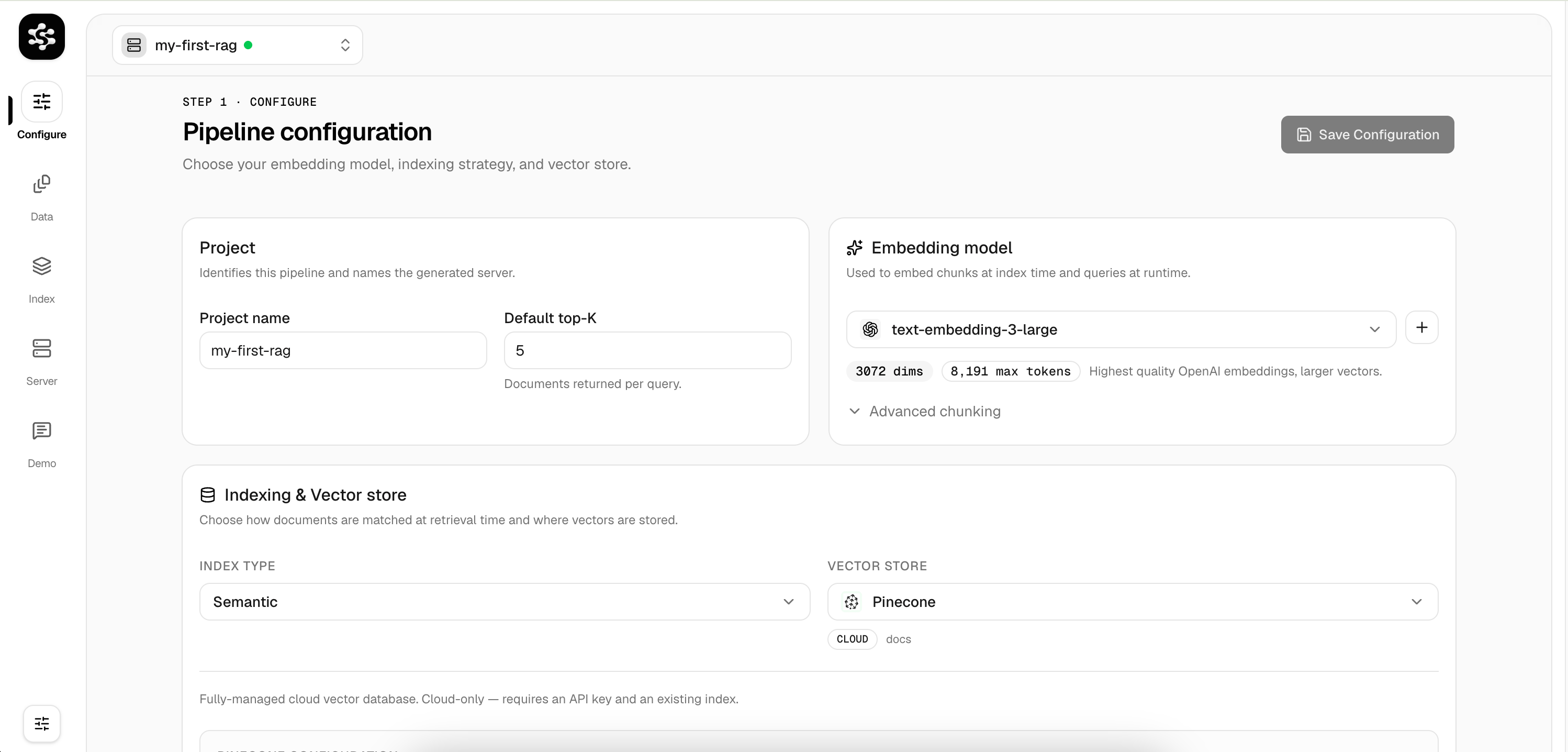
Ingest Data
In the Data tab, add documents via file upload, direct text input, or web scraping. These queue up for the ETL process.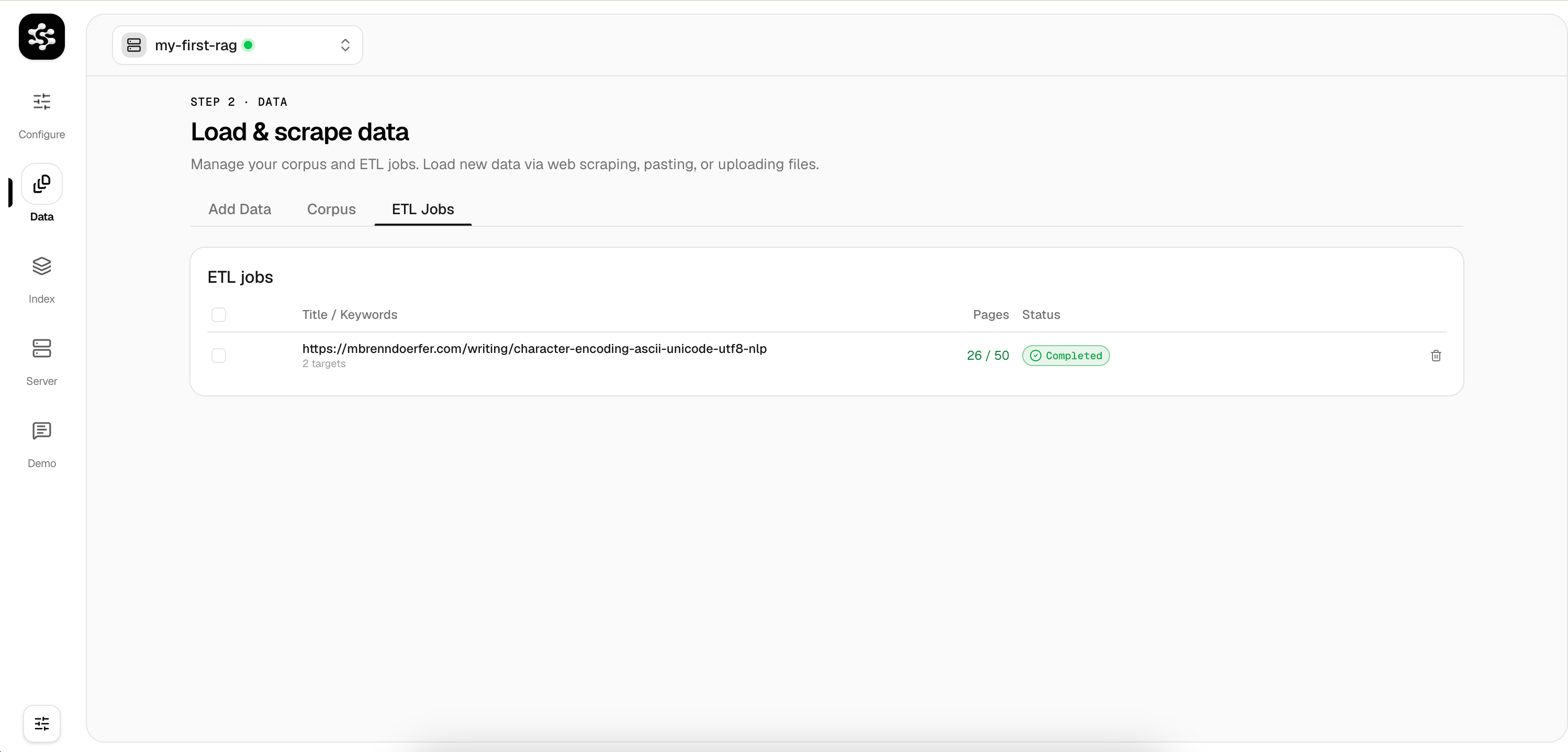
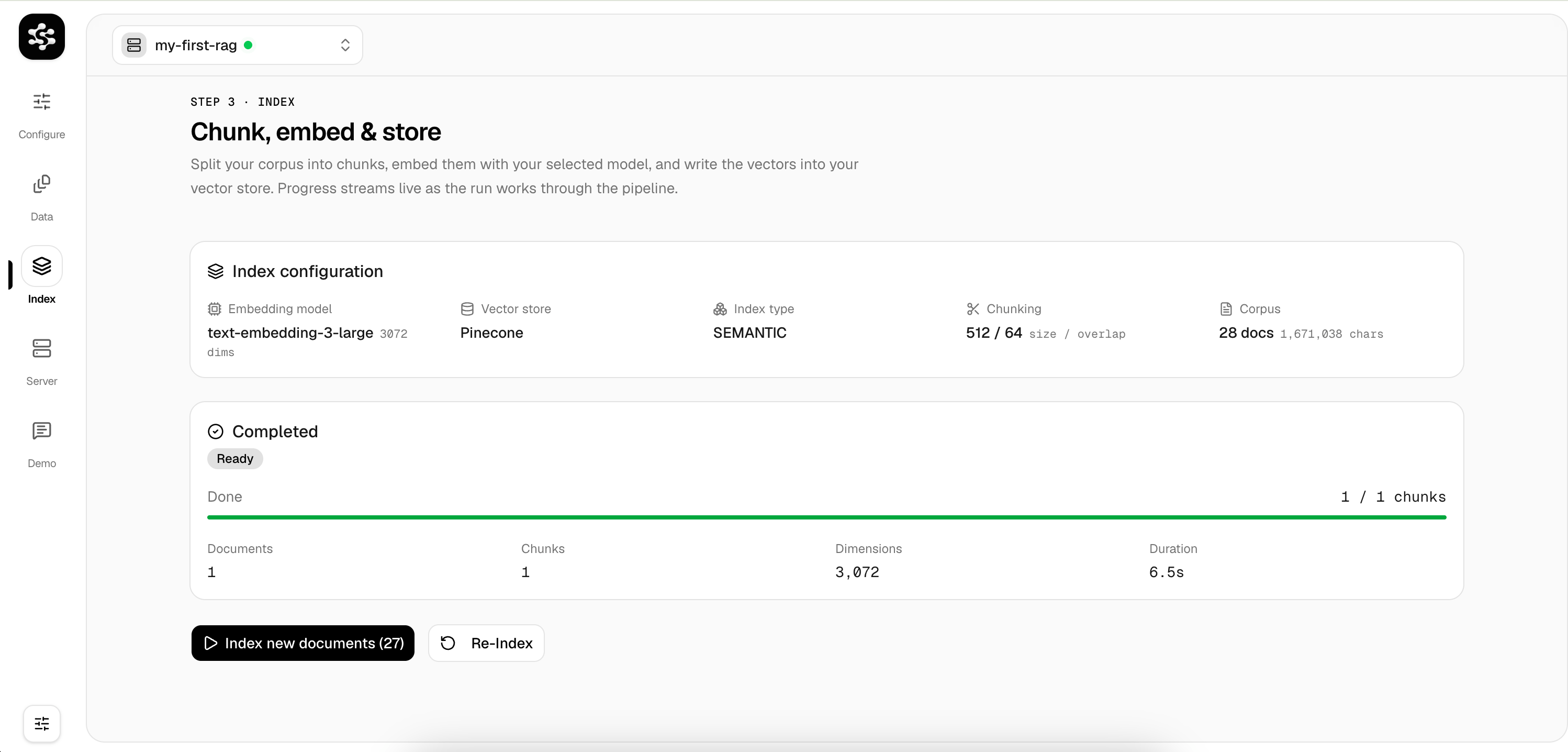
Index
Head to the Index tab and click Run Indexing Job to chunk your documents and store the vectors.